
Search engines discover, analyze and organize the content available on the internet to offer relevant results that satisfy the search queries.
For websites to show up in search results the content first has to be visible to the search engines. This is possibly one of the most important pieces in the SEO puzzle – if your website is not detected by a search engine then there is no way that it will show in the search engine results page (SERPs).
So, to keep the results as relevant as possible for the users, search engines have a process in place to identify the best web pages for a search query. To make the most of your SEO efforts, it is important to understand what this process is and how it works.
Therefore, today we will talk about how the search engine works on a website and what are the different stages involved in the whole procedure.
How Does Search Engine Work?
To put it simply, search engines have a three-step process to identify and rank a website. This process includes:
Crawling – Internet bots browse the internet to find and identify web pages
Analyzing – Calculating and comprehending the quality and popularity of a website
Indexing – Storing and organizing information regarding all the discovered pages for future retrieval
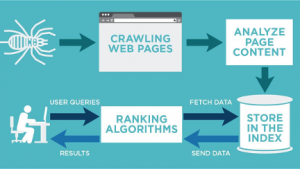
Image source: https://1.bp.blogspot.com/
Now let’s discuss these concepts in detail.
What is Web Crawling?
Crawling is the process of discovering web pages by using a team of robots known as web crawlers or spiders.
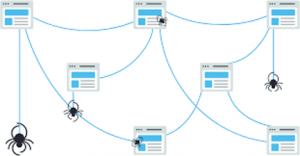
Image Source: https://moz.com/
Robot.txt is the main robot exclusion protocol (REP) which is a set of web standards that regulate how the robots crawl the web. These robots bind together different web pages across the internet. This creates a pathway for search engine crawlers to access trillions of interconnected web pages on the World Wide Web (www).
What is Search Engine Analyzing?
To discover, categorize and rank the trillions of websites available on the internet, search engines use algorithms that assess the quality and relevancy of a web page. This is a complex and advanced process of identifying and sorting data in a way that will be easy for the end-user to understand.
Search engines analyze websites by looking at different factors based on users’ search intent. These factors include relevancy to search query, content quality, website speed, metadata and more. All such factors allow search engines to calculate and assess the overall quality of a web page and then use these calculations to determine the ranking on SERPs.
To discover how Google analyses your website, use Google analytics which will give you all the relevant data for site search analysis. These analytics reports can be very helpful in creating a strong SEO strategy to enhance your website ranking.
What is Indexing?
Once the website has been crawled and analyzed, search engines then decide how to categorize and organize the gathered information. Based on the calculations received from website analysis, the search engine then reviews whether the website has positive or negative ranking signals.
Search engine indexing includes:
- Detailed information on the nature of the content available on the website and its relevance
- Structural map of all the web pages that a website links to
- The anchor text of all the links
- Detailed data about links such as ads or no ads, location of Ads on a webpage, inbound links and their implication and much more.
Googlebot is a Google web crawler that discovers websites and follows the linking web pages on those websites to discover new URLs. By going to new links Googlebot creates a path of finding content that it adds to its index called Caffeine – an enormous database of discovered URLs.
Note that once a website has been included in the index it can be removed due to various reasons:
- URL returning a server error (5XX) or not found error (4XX)
- URL having a no-index meta tag which is added by site owners to instruct the search engine to omit the page from its index
- URL has been penalized for violating the webmaster guidelines of a search engine
- URL is blocked from crawling for any reason
To check the indexing status and visibility of a website on Google you can use Google search console. It is a web service by Google which helps you measure the search traffic and performance of your website on Google. It also allows you to fix indexing issues to make your website rank better in Google search results.
Why Is It Important To Know How A Search Engine Works?
By now you know that the purpose of a search engine is to provide useful and most relevant answers to a user’s search query in the best way possible. Digital marketers, webmasters, and website owners have been trying to understand and manipulate how search engines work for many years. The reason behind this is to strengthen and improve their SEO strategies in order to get higher search engine rankings. This is because the higher the ranking the more traffic a website gets.
Thus, by understanding how search engines work you can improve the website ranking in SERPs which will result in more traffic, better online reputation, increased lead generation, and ultimately more profit.
At face value, search engines seem so simple: type a search query and within seconds you get the desired results. What looks apparently so simple is backed up by a complex process that helps identify the most relevant data to the search intent so that users get the best-desired results as efficiently and accurately as possible.
But why should you care how this process works?
Understanding the fundamentals of crawling, analyzing and indexing can help you better improve on your SEO performance for ranking higher in search engine results.